Table of Contents
PART 1 — सांख्यिकी (Statistics) परिचय
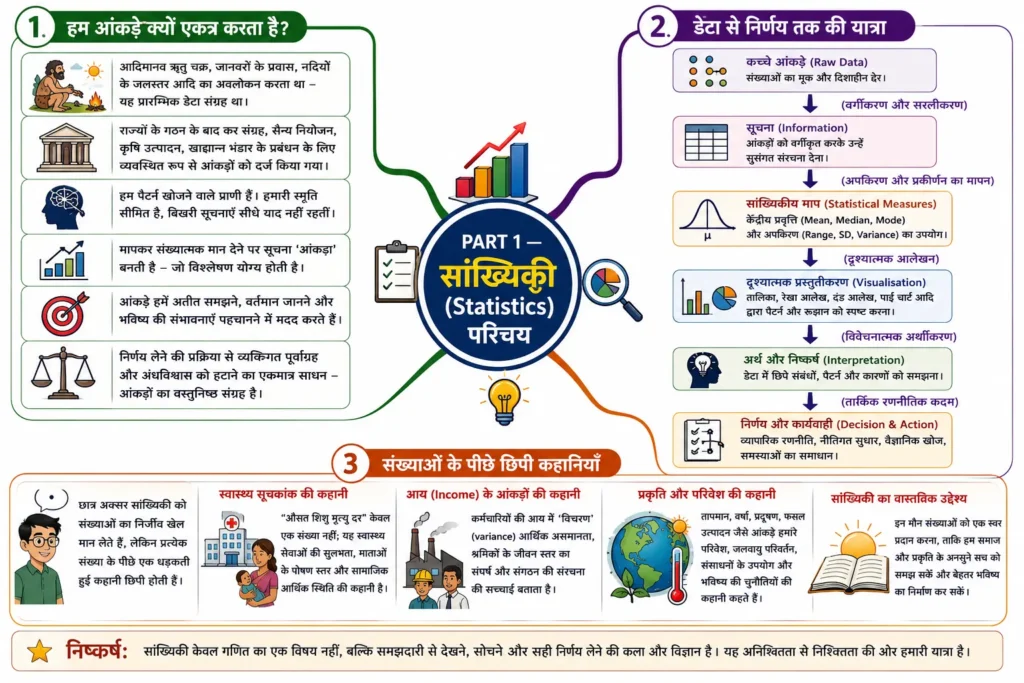
1. हम आंकड़े क्यों एकत्र करता है?
मानव इतिहास वास्तव में अनिश्चितता को कम करने और अस्तित्व को सुरक्षित बनाने का इतिहास रहा है । प्राचीन सभ्यताओं से लेकर आधुनिक डिजिटल युग तक, हम निरंतर अपने परिवेश का अवलोकन करता आया है। आदिमानव जब ऋतु चक्र, जंगली जानवरों के प्रवास के समय, और नदियों के जलस्तर का अवलोकन करता था, तो वह अनजाने में ही डेटा एकत्र कर रहा होता था। समय के साथ जब राज्यों का गठन हुआ, तो कर संग्रह, सैन्य नियोजन, कृषि उत्पादन और खाद्यान्न के भंडार के प्रबंधन के लिए व्यवस्थित रूप से आंकड़ों को दर्ज करने की आवश्यकता महसूस की गई।
हम मूलतः पैटर्न (प्रतिरूप) खोजने वाला प्राणी है। हमारी संज्ञानात्मक क्षमताएं एक सीमा के बाद बिखरी हुई सूचनाओं को सीधे याद रखने में असमर्थ हो जाती हैं । जब हम किसी घटना को मापकर उसे संख्यात्मक मान देते हैं, तो वह हमारी सीमित स्मृति से बाहर निकलकर विश्लेषण योग्य ‘आंकड़ा’ बन जाता है । आंकड़े हमें यह समझने की शक्ति देते हैं कि अतीत में क्या हुआ था, वर्तमान में क्या चल रहा है, और आने वाले समय में किस प्रकार की संभावनाएं आकार ले सकती हैं । निर्णय लेने की प्रक्रिया में से व्यक्तिगत पूर्वाग्रह और अंधविश्वास को हटाने का एकमात्र साधन आंकड़ों का वस्तुनिष्ठ संग्रह ही है ।
2. डेटा से निर्णय तक की यात्रा
│
▼ (वर्गीकरण और सरलीकरण)
│
▼ (अपकिरण और प्रकीर्णन का मापन)
│
▼ (दृश्यात्मक आलेखन)
│
▼ (विवेचनात्मक अर्थीकरण)
│
▼ (तार्किक रणनीतिक कदम)
कच्चे आंकड़े अपने आप में मूक और दिशाहीन होते हैं । वे संख्याओं का एक ऐसा विशाल ढेर होते हैं जिसे देखकर कोई निष्कर्ष नहीं निकाला जा सकता। इस मूक मलबे से व्यावहारिक निर्णय तक पहुँचने की यात्रा एक सुव्यवस्थित वैज्ञानिक और मानसिक प्रक्रिया है। जब हम इन कच्चे आंकड़ों को वर्गीकृत करके उन्हें सुसंगत संरचना प्रदान करते हैं, तो वे सूचना में बदलते हैं । इस सूचना पर जब केंद्रीय प्रवृत्ति और अपकिरण के मापों का अनुप्रयोग किया जाता है, तो आंकड़ों के बीच के आंतरिक संबंध स्पष्ट होते हैं । अंततः, यह सांख्यिकीय निष्कर्ष एक व्यावहारिक निर्णय का आधार बनता है, जो किसी व्यापारिक रणनीति, नीतिगत सुधार या वैज्ञानिक खोज को दिशा प्रदान करता है ।
3. संख्याओं के पीछे छिपी कहानियाँ
मेरे वर्षों के classroom अनुभव में मैंने यह पाया है कि छात्र अक्सर सांख्यिकी को संख्याओं का एक निर्जीव खेल मान लेते हैं। लेकिन वास्तव में, प्रत्येक संख्या के पीछे एक धड़कती हुई कहानी, एक वास्तविक मानवीय परिस्थिति या एक गतिशील भौतिक सच्चाई छिपी होती है । जब हम किसी देश में “औसत शिशु मृत्यु दर” का सूचकांक देखते हैं, तो वह केवल एक दशमलव संख्या नहीं है; वह देश की स्वास्थ्य सेवा प्रणाली की सुलभता, माताओं के पोषण स्तर और सामाजिक आर्थिक स्थिति की मार्मिक कहानी कह रही होती है।
जब मैं सांख्यिकी पढ़ाता हूँ, तो मैं हमेशा छात्रों से कहता हूँ कि वे संख्याओं को केवल परीक्षा के दृष्टिकोण से हल किए जाने वाले प्रतीकों के रूप में न देखें। एक कारखाने के कर्मचारियों की आय के आंकड़ों में छुपा हुआ ‘विचरण’ (variance) उस कारखाने में व्याप्त आर्थिक असमानता और श्रमिकों के जीवन स्तर के संघर्ष की कहानी बयां करता है । सांख्यिकी का वास्तविक उद्देश्य इन मौन संख्याओं को एक स्वर प्रदान करना है ताकि वे हमारे समाज और प्रकृति के अनसुने सच को हमारे सामने उजागर कर सकें ।
PART 2 — आंकड़ों की दुनिया
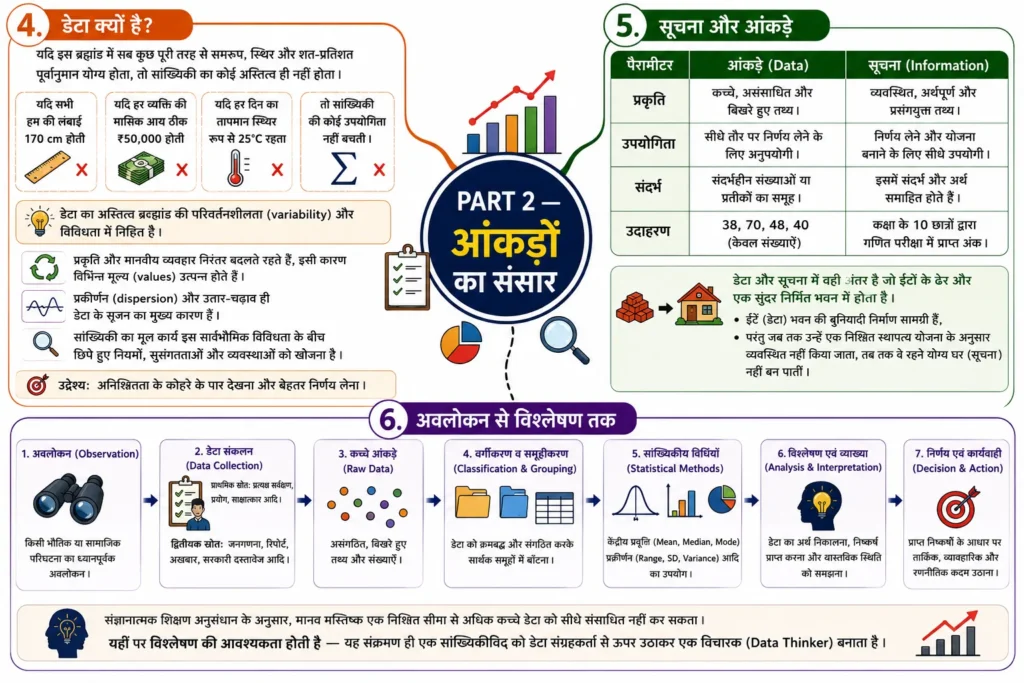
4. डेटा क्यों है?
यदि इस ब्रह्मांड में सब कुछ पूरी तरह से समरूप, स्थिर और शत-प्रतिशत पूर्वानुमान योग्य होता, तो सांख्यिकी का कोई अस्तित्व ही नहीं होता। यदि सभी हमें की लंबाई बिल्कुल $170 \text{ cm}$ होती, प्रत्येक व्यक्ति की मासिक आय ठीक ₹$50,000$ होती, और हर दिन का तापमान स्थिर रूप से $25^\circ\text{C}$ रहता, तो सांख्यिकी की कोई उपयोगिता नहीं बचती ।
डेटा का अस्तित्व ब्रह्मांड की परिवर्तनशीलता (variability) और विविधता में निहित है । प्रकृति और मानवीय व्यवहार निरंतर बदलते रहते हैं, और इस बदलाव के कारण ही विभिन्न मूल्य (values) उत्पन्न होते हैं। प्रकीर्णन (dispersion) और उतार-चढ़ाव ही डेटा के सृजन का मुख्य कारण हैं । सांख्यिकी का मूल कार्य इस सार्वभौमिक विविधता के बीच छिपे हुए नियमों, सुसंगतताओं और व्यवस्थाओं को खोजना है ताकि हम अनिश्चितता के कोहरे के पार देख सकें ।
5. सूचना और आंकड़े
| पैरामीटर | आंकड़े (Data) | सूचना (Information) |
| प्रकृति | कच्चे, असंसाधित और बिखरे हुए तथ्य । | व्यवस्थित, अर्थपूर्ण और प्रसंगयुक्त तथ्य । |
| उपयोगिता | सीधे तौर पर निर्णय लेने के लिए अनुपयोगी । | निर्णय लेने और योजना बनाने के लिए सीधे उपयोगी । |
| संदर्भ | संदर्भहीन संख्याओं या प्रतीकों का समूह । | इसमें संदर्भ और अर्थ समाहित होते हैं । |
| उदाहरण | $38, 70, 48, 40$ (केवल संख्याएँ) । | कक्षा के 10 छात्रों द्वारा गणित परीक्षा में प्राप्त अंक । |
डेटा और सूचना में वही अंतर है जो ईंटों के ढेर और एक सुंदर निर्मित भवन में होता है। ईंटें (डेटा) भवन की बुनियादी निर्माण सामग्री हैं, लेकिन जब तक उन्हें एक निश्चित स्थापत्य योजना के अनुसार व्यवस्थित नहीं किया जाता, तब तक वे रहने योग्य घर (सूचना) नहीं बन पातीं ।
6. अवलोकन से विश्लेषण तक
सांख्यिकी की प्रक्रिया किसी भौतिक या सामाजिक परिघटना के ध्यानपूर्वक अवलोकन (observation) से प्रारंभ होती है । यह अवलोकन प्राथमिक स्रोतों (जैसे प्रत्यक्ष सर्वेक्षण) या द्वितीयक स्रोतों (जैसे सरकारी जनगणना दस्तावेजों) के माध्यम से हो सकता है । परंतु केवल अवलोकन एकत्र कर लेना सांख्यिकी का अंत नहीं है।
संज्ञानात्मक शिक्षण अनुसंधान (cognitive learning research) के अनुसार, मानव मस्तिष्क एक निश्चित सीमा से अधिक कच्चे डेटा को सीधे संसाधित नहीं कर सकता। यहीं पर विश्लेषण (analysis) की आवश्यकता होती है। विश्लेषण के अंतर्गत हम कच्चे आंकड़ों को समूहीकृत करते हैं, उनके केंद्रीय रुझानों को मापते हैं, और उनके फैलाव का वस्तुनिष्ठ मूल्यांकन करते हैं । यह संक्रमण ही एक सांख्यिकीविद् को केवल डेटा संग्रहकर्ता से ऊपर उठाकर एक विचारक (Data Thinker) बनाता है।
PART 3 — सामान्य प्रवृत्ति का दर्पण

7. औसत का उत्तपत्ति
हम जब एक साथ अनेक भिन्न-भिन्न सूचनाओं को देखता है, तो उसका मस्तिष्क जटिलता को कम करने के लिए एक सरल ‘प्रतिनिधि मान’ (representative value) की खोज करता है। इसी संज्ञानात्मक सरलीकरण (cognitive simplification) की आवश्यकता ने ‘औसत’ या ‘केंद्रीय प्रवृत्ति’ (Central Tendency) की अवधारणा को जन्म दिया। औसत एक ऐसी एकल संख्या है जो पूरे समूह की सामूहिक विशेषता को अपने भीतर समाहित करने का प्रयास करती है। यह विविधता के बीच सुसंगतता खोजने का एक प्राथमिक मानवीय प्रयास है।
8. Mean की वास्तविक समझ
समांतर माध्य, जिसे हम सामान्य भाषा में ‘माध्य’ (Mean) कहते हैं, सांख्यिकी का सबसे बुनियादी और व्यापक रूप से प्रयुक्त होने वाला माप है । गणितीय रूप से, यह सभी प्रेक्षणों के योग को प्रेक्षणों की कुल संख्या से विभाजित करके प्राप्त किया जाता है:
$$\bar{x} = \frac{\sum_{i=1}^{n} x_i}{n}$$
परंतु भौतिक दृष्टि से, समांतर माध्य वास्तव में क्या है? जब मैं Mean पढ़ाता हूँ, तो मैं छात्रों को इसे एक तराजू के भौतिक संतुलन बिंदु या भौतिक विज्ञान के द्रव्यमान केंद्र (Center of Mass) के रूप में कल्पना करने के लिए कहता हूँ।
यदि हम एक भारहीन सीधी पटरी पर भिन्न-भिन्न स्थानों पर अलग-अलग वजन (जो डेटा बिंदुओं को दर्शाते हैं) रखें, तो वह पटरी जिस एकमात्र बिंदु पर पूरी तरह से संतुलित होकर सीधी खड़ी रहेगी, वही बिंदु उस डेटा का समांतर माध्य ($\bar{x}$) होगा। यही कारण है कि समांतर माध्य से सभी प्रेक्षणों के विचलनों का योग हमेशा शून्य होता है:
$$\sum_{i=1}^{n} (x_i – \bar{x}) = 0$$
यह समीकरण कोई सामान्य गणितीय सूत्र नहीं है, बल्कि यह इस सत्य का प्रकटीकरण है कि समांतर माध्य आंकड़ों का वह पूर्ण गुरुत्व केंद्र है जहाँ धनात्मक और ऋणात्मक बल एक-दूसरे को संतुलित कर देते हैं।
9. Mean की सीमाएँ: “औसत का भ्रम” (The Average Illusion)
एक observation जो वर्षों में मैंने notice की है, वह यह है कि छात्र अक्सर समांतर माध्य को एक सर्वगुण संपन्न और अचूक माप मान लेते हैं। लेकिन वास्तव में, समांतर माध्य की अपनी गंभीर सीमाएँ हैं। यह चरम मानों (Outliers/Extreme Values) के प्रति अत्यंत संवेदनशील होता है ।
मान लीजिए कि एक कमरे में $5$ छोटे व्यवसायी बैठे हैं, जिनमें से प्रत्येक की मासिक आय ₹$30,000$ है। यहाँ औसत आय स्पष्ट रूप से ₹$30,000$ है। अब यदि उस कमरे में देश का सबसे अमीर उद्योगपति प्रवेश करता है, जिसकी मासिक आय ₹$60\text{ करोड़}$ है, तो अचानक उस कमरे में बैठे $6$ लोगों की औसत मासिक आय बढ़कर ₹$1\text{ करोड़}$ से अधिक हो जाएगी।
गणितीय रूप से यह बिल्कुल सत्य है, परंतु व्यावहारिक रूप से यह एक भयानक भ्रम है। कमरे में बैठे $5$ सामान्य व्यवसायी अभी भी अपनी बुनियादी जरूरतों के लिए संघर्ष कर रहे हैं, लेकिन सांख्यिकीय औसत उन्हें करोड़पति दिखा रहा है। इसे ही “औसत का भ्रम” (Average Illusion) कहा जाता है । यही कारण है कि केवल माध्य पर भरोसा करना नीति निर्माताओं और व्यापारियों के लिए अत्यधिक जोखिम भरा हो सकता है।
PART 4 — मध्य संतुलन का संकेत
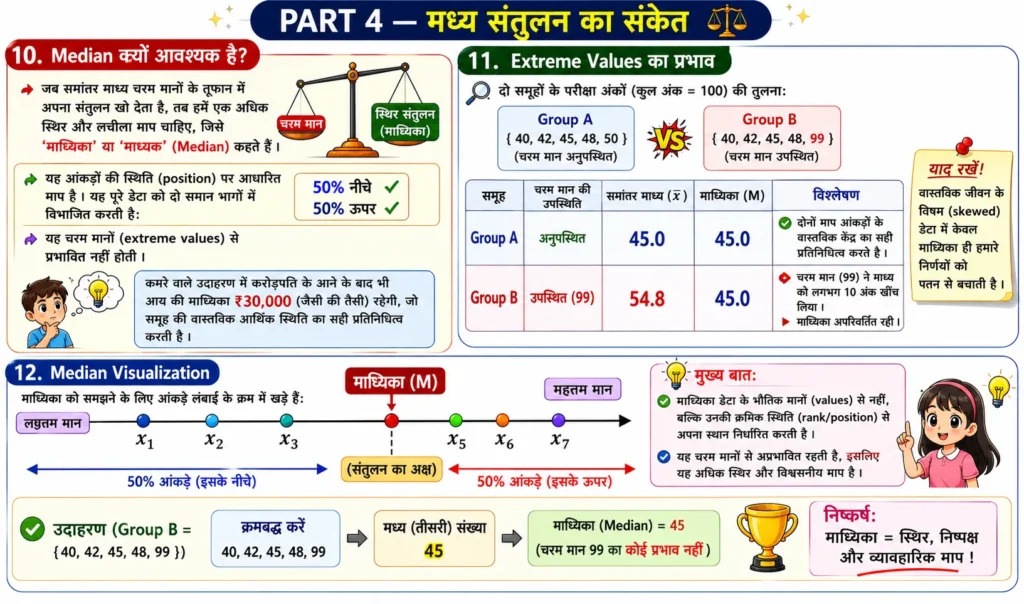
10. Median क्यों आवश्यक है?
जब समांतर माध्य चरम मानों के तूफान में अपना संतुलन खो देता है, तब हमें केंद्रीय प्रवृत्ति के एक अधिक स्थिर और लचीले माप की आवश्यकता होती है, जिसे ‘माध्यिका’ या ‘माध्यक’ (Median) कहा जाता है । माध्यिका आंकड़ों की स्थिति (position) पर आधारित माप है। यह पूरे डेटा सेट को दो समान भागों में इस प्रकार विभाजित करती है कि $50\%$ आंकड़े इसके नीचे होते हैं और $50\%$ इसके ऊपर ।
माध्यिका की आवश्यकता इसलिए है क्योंकि यह चरम मानों (extreme values) से प्रभावित नहीं होती। ऊपर वर्णित कमरे वाले उदाहरण में, अरबपति के आने के बाद भी यदि हम आय की माध्यिका निकालेंगे, तो वह ₹$30,000$ के आसपास ही रहेगी, जो उस समूह की वास्तविक आर्थिक स्थिति का कहीं अधिक सटीक और व्यावहारिक प्रतिनिधित्व करती है।
11. Extreme Values का प्रभाव
मान लीजिए कि हमारे पास दो अलग-अलग छात्रों के समूहों के परीक्षा अंकों का डेटा है, जहाँ कुल अंक $100$ हैं:
$$\text{Group A} = \{40, 42, 45, 48, 50\}$$
$$\text{Group B} = \{40, 42, 45, 48, 99\}$$
आइए इन दोनों समूहों के माध्य और माध्यिका की तुलना करके चरम मान ($99$) के प्रभाव का सूक्ष्म विश्लेषण करते हैं:
| समूह | चरम मान की उपस्थिति | समांतर माध्य (xˉ) | माध्यिका (M) | विश्लेषण |
| Group A | अनुपस्थित | $45.0$ | $45.0$ | दोनों माप आंकड़ों के वास्तविक केंद्र का सही प्रतिनिधित्व करते हैं। |
| Group B | उपस्थित ($99$) | $54.8$ | $45.0$ | चरम मान ने माध्य को लगभग $10$ अंक खींच लिया, जबकि माध्यिका अपरिवर्तित रही। |
यहाँ कमजोर students आमतौर पर भ्रमित हो जाते हैं। वे सोचते हैं कि चूँकि माध्यिका केवल बीच की संख्या चुनती है, इसलिए यह कम वैज्ञानिक है। परंतु Board copies check करते समय मैंने देखा है कि वास्तविक जीवन के परिदृश्यों में जहाँ डेटा अत्यधिक विषम (skewed) होता है, वहाँ केवल माध्यिका ही हमारे निर्णयों को पतन से बचाती है।
12. Median Visualization
सांख्यिकी में माध्यिका को दृष्टिगत रूप से समझने के लिए एक सरल रैखिक संतुलन प्रतिरूप का उपयोग किया जा सकता है। मान लीजिए कि आंकड़े लंबाई के क्रम में खड़े हैं:
लघुत्तम मान महत्तम मान
├───────────┼───────────┼───────────[ माध्यिका (M) ]───────────┼───────────┼───────────┤
x_1 x_2 x_3 │ x_5 x_6 x_7
▼
(संतुलन का अक्ष)
◄───────────── 50% आंकड़े ─────────────► │ ◄───────────── 50% आंकड़े ─────────────►
यह दृश्य प्रारूप स्पष्ट रूप से दर्शाता है कि माध्यिका डेटा के भौतिक मानों से प्रभावित होने के स्थान पर उनकी क्रमिक स्थिति (rank or position) से अपना स्थान निर्धारित करती है ।
PART 5 — सबसे प्रचलित व्यवहार का गणित
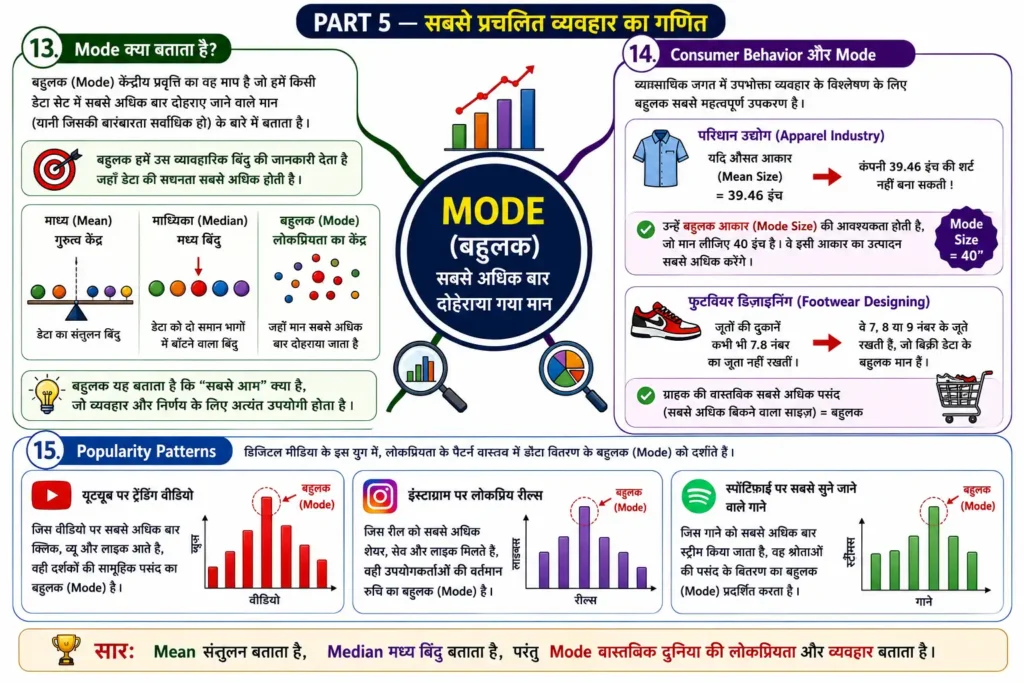
13. Mode क्या बताता है?
बहुलक (Mode) केंद्रीय प्रवृत्ति का वह माप है जो हमें किसी डेटा सेट में सबसे अधिक बार दोहराए जाने वाले मान (यानी जिसकी बारंबारता सर्वाधिक हो) के बारे में बताता है। बहुलक हमें उस व्यावहारिक बिंदु की जानकारी देता है जहाँ डेटा की सघनता सबसे अधिक होती है। यदि माध्य ‘गुरुत्व केंद्र’ है और माध्यिका ‘मध्य बिंदु’ है, तो बहुलक वास्तव में ‘लोकप्रियता का केंद्र’ है।
14. Consumer Behavior और Mode
व्यावसायिक जगत में उपभोक्ता व्यवहार (Consumer Behavior) का विश्लेषण करने के लिए बहुलक सबसे महत्वपूर्ण उपकरण है। कोई भी व्यवसाय केवल औसत के भरोसे नहीं चल सकता।
- परिधान उद्योग (Apparel Industry): यदि एक रेडीमेड कपड़ा निर्माता कंपनी को यह पता चले कि भारतीय पुरुषों की शर्ट का ‘औसत आकार’ $39.46 \text{ इंच}$ है, तो वह इस आकार की शर्ट का निर्माण नहीं कर सकती। उन्हें ‘बहुलक आकार’ (Mode Size) की आवश्यकता होती है, जो मान लीजिए कि $40$ है। वे इसी आकार का उत्पादन सबसे अधिक करेंगे।
- फुटवियर डिज़ाइनिंग: जूतों की दुकानें कभी भी $7.8$ नंबर का जूता नहीं रखतीं। वे $7$, $8$ या $9$ नंबर के जूते रखती हैं, जो बिक्री डेटा के बहुलक मान हैं 。
15. Popularity Patterns
डिजिटल मीडिया के इस युग में, यूट्यूब पर ‘ट्रेंडिंग वीडियो’, इंस्टाग्राम पर सबसे अधिक लोकप्रिय रील्स, या स्पॉटिफ़ाई पर सबसे ज्यादा सुने जाने वाले गाने वास्तव में डेटा वितरण के बहुलक (Mode) को दर्शाते हैं। ये बिंदु सामाजिक प्राथमिकताओं के सबसे घने संचय को प्रदर्शित करते हैं।
PART 6 — पुनरावृत्ति का प्रतिरूप
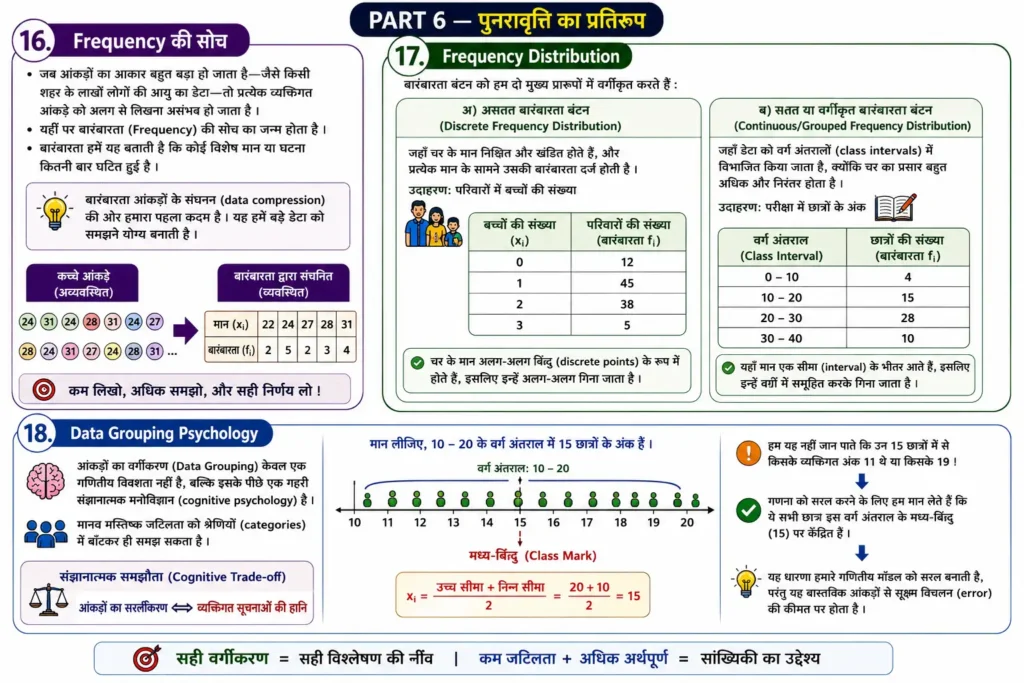
16. Frequency की सोच
जब आंकड़ों का आकार बहुत बड़ा हो जाता है—जैसे किसी शहर के लाखों लोगों की आयु का डेटा—तो प्रत्येक व्यक्तिगत आंकड़े को अलग से लिखना असंभव हो जाता है। यहीं पर बारंबारता (Frequency) की सोच का जन्म होता है। बारंबारता हमें यह बताती है कि कोई विशेष मान या घटना कितनी बार घटित हुई है । यह आंकड़ों के संघनन (data compression) की ओर हमारा पहला कदम है।
17. Frequency Distribution
बारंबारता बंटन को हम दो मुख्य प्रारूपों में वर्गीकृत करते हैं :
अ) असतत बारंबारता बंटन (Discrete Frequency Distribution)
जहाँ चर के मान निश्चित और खंडित होते हैं, और प्रत्येक मान के सामने उसकी बारंबारता दर्ज होती है । उदाहरण के लिए, परिवारों में बच्चों की संख्या:
| बच्चों की संख्या (xi) | परिवारों की संख्या (बारंबारता fi) |
| $0$ | $12$ |
| $1$ | $45$ |
| $2$ | $38$ |
| $3$ | $5$ |
ब) सतत या वर्गीकृत बारंबारता बंटन (Continuous/Grouped Frequency Distribution)
जहाँ डेटा को वर्ग अंतरालों (class intervals) में विभाजित किया जाता है, क्योंकि चर का प्रसार बहुत अधिक और निरंतर होता है । उदाहरण के लिए, परीक्षा में छात्रों के अंक:
| वर्ग अंतराल (Class Interval) | छात्रों की संख्या (बारंबारता fi) |
| $0-10$ | $4$ |
| $10-20$ | $15$ |
| $20-30$ | $28$ |
| $30-40$ | $10$ |
18. Data Grouping Psychology
आंकड़ों का वर्गीकरण (Data Grouping) केवल एक गणितीय विवशता नहीं है, बल्कि इसके पीछे एक गहरी संज्ञानात्मक मनोविज्ञान (cognitive psychology) है । मानव मस्तिष्क जटिलता को श्रेणियों में बाँटकर ही समझ सकता है।
परंतु इस वर्गीकरण प्रक्रिया में एक महत्वपूर्ण संज्ञानात्मक समझौता (Cognitive Trade-off) शामिल होता है:
आंकड़ों का सरलीकरण $$ \iff $$ व्यक्तिगत सूचनाओं की हानि
जब हम $10-20$ के वर्ग अंतराल में $15$ छात्रों को रखते हैं, तो हम यह नहीं जान पाते कि उन $15$ छात्रों में से किसके व्यक्तिगत अंक $11$ थे या किसके $19$ । सांख्यिकी की गणनाओं को आगे बढ़ाने के लिए हम यह मान लेते हैं कि ये सभी $15$ छात्र इस वर्ग अंतराल के मध्य-बिंदु यानी वर्ग चिह्न (Class Mark $x_i = \frac{\text{उच्च सीमा} + \text{निम्न सीमा}}{2}$) पर केंद्रित हैं । यह धारणा हमारे गणितीय मॉडल को सरल बनाती है, परंतु यह वास्तविक आंकड़ों से सूक्ष्म विचलन की कीमत पर होता है।
PART 7 — संख्याओं के पीछे छिपी कहानी

19. Graph Reading Skills
ग्राफ पढ़ना आधुनिक साक्षरता का एक अनिवार्य हिस्सा है। एक कुशल सांख्यिकीविद् के रूप में, ग्राफ देखना मेरे लिए किसी भाषा के उपन्यास को पढ़ने जैसा है। ग्राफ केवल ज्यामितीय आकृतियाँ नहीं हैं, वे दो या दो से अधिक चरों के बीच के बदलते संबंधों की गतिशीलता को प्रदर्शित करते हैं । ग्राफ को पढ़ते समय हमें उसकी ढाल (slope), अक्षों के पैमाने (axes scale), और डेटा के झुकाव को समझने की दृष्टि विकसित करनी चाहिए ।
20. Data Visualization
कक्षा 11 गणित अध्याय 13 के पाठ्यक्रम में तीन प्रकार के आलेखीय निरूपण अत्यंत महत्वपूर्ण हैं :
- हिस्टोग्राम (Histogram): वर्गीकृत आंकड़ों का सबसे उत्कृष्ट दृश्यात्मक रूप, जहाँ स्तंभों का क्षेत्रफल बारंबारता के सीधे समानुपाती होता है।
- बारंबारता बहुभुज (Frequency Polygon): सतत बारंबारता बंटन के उतार-चढ़ाव और उसकी समग्र प्रवृत्ति को एक सतत रेखा के माध्यम से दर्शाने का बेहतरीन साधन।
- संचयी बारंबारता वक्र या तोरण (Ogive Curve): यह हमें यह देखने की अनुमति देता है कि डेटा का कितना प्रतिशत एक निश्चित मान से कम या अधिक है। इसके प्रतिच्छेदन बिंदु से हम सीधे माध्यिका भी ज्ञात कर सकते हैं ।
21. Graph Manipulation Awareness
समाचार माध्यमों, सोशल मीडिया और विज्ञापनों में अक्सर आंकड़ों को इस तरह से प्रस्तुत किया जाता है कि वे सत्य को तोड़-मरोड़कर पेश करें । इसे “आलेखीय हेरफेर” (Graphical Manipulation) कहा जाता है।
एक सबसे सामान्य हेरफेर है “Y-अक्ष को काटना” (Truncating the Y-axis)।
भ्रामक आलेख (Y-Axis 80 से प्रारंभ) ईमानदार आलेख (Y-Axis 0 से प्रारंभ)
100 | [तीव्र उछाल?] 100 | [स्थिर प्रदर्शन]
95 | ┌──┐ 80 |
90 | ┌──┐ │ │ 60 |
85 | │ │ │ │ 40 | ┌──┐ ┌──┐
80 |____└──┴──└──┴___ 20 | │ │ │ │
वर्ष A वर्ष B 0 |____└──┴──└──┴___
वर्ष A वर्ष B
बाएं वाले आलेख में ऐसा लगता है कि वर्ष B में बहुत बड़ी वृद्धि हुई है, जबकि वास्तव में वह वृद्धि मात्र $5\%$ की थी, जिसे दाएं वाले आलेख में ईमानदारी से दर्शाया गया है। डेटा थिंकिंग छात्रों को ऐसे दृश्यात्मक जालों से सचेत रहने की क्षमता प्रदान करती है ।
PART 8 — वास्तविक जीवन अनुप्रयोग

22. Cricket Statistics (IPL Player Analysis)
क्रिकेट के मैदान पर जब आईपीएल फ्रेंचाइजी खिलाड़ियों पर करोड़ों की बोली लगाती हैं, तो वे केवल खिलाड़ी के नाम पर नहीं, बल्कि उसके अपकिरण के मापों पर बोली लगाती हैं।
मान लेते हैं कि हमारे पास दो बल्लेबाज X और Y हैं, जिनके अंतिम $5$ मैचों के स्कोर इस प्रकार हैं:
- $$\text{बल्लेबाज X} = \{48, 50, 52, 49, 51\}$$*$$\text{बल्लेबाज Y} = \{0, 100, 10, 130, 10\}$$
आइए इनकी तुलना करते हैं:
$$\bar{x} (X) = \frac{48+50+52+49+51}{5} = 50$$
$$\bar{x} (Y) = \frac{0+100+10+130+10}{5} = 52$$
औसत को देखकर ऐसा लग सकता है कि बल्लेबाज Y बेहतर है क्योंकि उसका औसत ($52$) अधिक है। लेकिन बल्लेबाज X का मानक विचलन (Standard Deviation) अत्यंत कम है, जो उसकी असाधारण स्थिरता (consistency) को दर्शाता है । वहीं बल्लेबाज Y का मानक विचलन बहुत उच्च है, जो उसकी अस्थिरता (volatility) को दर्शाता है । टी-20 क्रिकेट की दुनिया में निरंतरता ही मैच जिताती है, और सांख्यिकी के ये उपकरण ही इस छिपे हुए सच को उजागर करते हैं 。
23. Election Surveys & Exit Polls
चुनावों के दौरान आने वाले एग्जिट पोल सांख्यिकी के प्रतिचयन सिद्धांत (Sampling Theory) का प्रत्यक्ष उदाहरण हैं। करोड़ों मतदाताओं की राय जानने के लिए एक छोटे और प्रतिनिधि नमूने (representative sample) का चयन किया जाता है। यदि इस नमूने के चयन में चयन पूर्वाग्रह (Selection Bias) शामिल हो जाए—जैसे केवल एक विशिष्ट क्षेत्र या वर्ग के लोगों से ही राय ली जाए—तो पूरे सर्वेक्षण के परिणाम भ्रामक हो जाते हैं, जैसा कि अतीत में कई बार देखा गया है 。
24. YouTube Analytics & Instagram Reach
यूट्यूब क्रिएटर स्टूडियो और इंस्टाग्राम डैशबोर्ड पूरी तरह सांख्यिकीय मॉडलों पर आधारित हैं। ‘क्लिक-थ्रू रेट’ (CTR) और ‘औसत दृश्य अवधि’ (Average View Duration) का संबंध सीधे माध्य और माध्यिका के व्यवहार से है। एल्गोरिदम यह देखता है कि क्या वीडियो पर बिताए गए समय का विचरण (variance) कम है, जिसका अर्थ है कि वीडियो अधिकांश दर्शकों को समान रूप से पसंद आ रहा है 。
25. Social Media Algorithms
फेसबुक और टिकटॉक जैसे प्लेटफॉर्म के एल्गोरिदम यह ट्रैक करते हैं कि आप किसी पोस्ट पर कितने मिलीसेकंड रुकते हैं। वे आपके समय के इस वितरण का प्रसरण (variance) मापते हैं। यदि आपके रुकने के समय का विचरण बहुत कम है (अर्थात आप लगातार उस प्रकार की सामग्री पर रुक रहे हैं), तो एल्गोरिदम आपके फीड को उसी प्रकार के विजुअल्स से भर देता है 。
26. AI Recommendation Systems (Netflix/Amazon)
जब नेटफ्लिक्स आपको कोई फिल्म सुझाता है या अमेज़न कोई उत्पाद दिखाता है, तो वे आपके पिछले डेटा के प्रकीर्णन (dispersion) और अन्य लाखों उपयोगकर्ताओं के डेटा के सहसंबंध (correlation) का सांख्यिकीय विश्लेषण कर रहे होते हैं। ये प्रणालियाँ आपकी प्राथमिकताओं का एक सांख्यिकीय नक्शा बनाती हैं, जिससे वे आपकी अगली पसंद का पहले ही सटीक अनुमान लगा लेती हैं।
27. Business Decisions & Census
सरकार द्वारा आयोजित की जाने वाली राष्ट्रीय जनगणना (Census) देश की नीतियों को तय करने वाली सबसे बड़ी सांख्यिकीय गतिविधि है । जनगणना से प्राप्त जनसंख्या की आयु, शिक्षा और आर्थिक स्थिति के डेटा का उपयोग करके ही नए अस्पतालों, स्कूलों और परिवहन व्यवस्थाओं के निर्माण का निर्णय लिया जाता है । कोई भी बड़ी व्यावसायिक कंपनी बाजार में प्रवेश करने से पहले इस सांख्यिकीय डेटा का सूक्ष्मता से अध्ययन करती है ।
PART 9 — छात्र मनोविज्ञान

28. Statistics Boring क्यों लगती है?
एक एजुकेशनल साइकोलॉजिस्ट (Educational Psychologist) के रूप में मैंने लंबे समय तक इस बात का अध्ययन किया है कि छात्र सांख्यिकी को उबाऊ क्यों मानते हैं। इसका मुख्य कारण हमारी पारंपरिक शिक्षण प्रणाली है जहाँ सांख्यिकी को केवल “सूत्रों के डंपिंग ग्राउंड” (formula dumping) के रूप में प्रस्तुत किया जाता है ।
छात्रों को सीधे तौर पर जटिल गणितीय सूत्र दे दिए जाते हैं, जैसे:
$$\sigma = \sqrt{\frac{\sum (x_i – \bar{x})^2}{n}}$$
बिना यह समझाए कि यह सूत्र प्रकीर्णन (dispersion) को मापने का एक कितना सुंदर और तार्किक प्रयास है । जब तक छात्र सांख्यिकी को अपने वास्तविक जीवन के डेटा (जैसे उनके मोबाइल स्क्रीन टाइम या उनके पसंदीदा क्रिकेटरों के स्कोर) से जोड़कर नहीं देखेंगे, तब तक उनके लिए यह केवल एक शुष्क विषय ही बना रहेगा ।
29. Formula याद करने के बाद भी उपयोग न कर पाना।
यहाँ बच्चे formula याद कर लेते हैं लेकिन data नहीं समझते। वे परीक्षा के तनाव में अक्सर सूत्रों को भूल जाते हैं या उनके बीच भ्रमित हो जाते हैं । वे रटने के इस जाल में फंसकर यह भूल जाते हैं कि सूत्र केवल एक भाषा है जो डेटा के स्वभाव को बयां कर रही है। उदाहरण के लिए, यदि छात्र यह समझ जाएं कि मानक विचलन वास्तव में माध्य से डेटा बिंदुओं की ‘औसत दूरी’ का एक परिष्कृत रूप है, तो वे कभी भी सूत्र के भूलने की बीमारी से पीड़ित नहीं होंगे ।
30. Data Thinking Recovery System
गणित में कमजोर छात्रों को वैचारिक स्पष्टता की ओर वापस लाने के लिए मैंने एक “डेटा थिंकिंग रिकवरी सिस्टम” विकसित किया है। यह प्रणाली संज्ञानात्मक अधिगम सिद्धांतों पर आधारित है:
[चरण 1: मूर्त अनुभव (Concrete Experience)] ──► छात्र स्वयं अपनी कक्षा के सहपाठियों के वजन का डेटा एकत्र करते हैं।
│
▼
[चरण 2: दृश्यात्मक आलेखन (Visual Mapping)] ──► इस डेटा को स्वयं बोर्ड पर हिस्टोग्राम के रूप में खींचते हैं।
│
▼
[चरण 3: अमूर्त सूत्रीकरण (Abstract Formula)] ──► इस दृश्य से स्वयं विचलन और प्रसरण के सूत्रों की आवश्यकता महसूस करते हैं।
इस त्रि-स्तरीय अधिगम चक्र से गुजरने के बाद कमजोर से कमजोर छात्र भी सांख्यिकीय सोच में पारंगत हो जाता है।
PART 10 — प्रतियोगी परीक्षा सेतु
31. CUET Data Interpretation
कॉमन यूनिवर्सिटी एंट्रेंस टेस्ट (CUET) में डेटा इंटरप्रिटेशन (DI) का एक बड़ा हिस्सा होता है । यहाँ जटिल सूत्रों के बजाय आपकी “डेटा साक्षरता” (Data Literacy) और त्वरित निर्णय लेने की क्षमता की परीक्षा ली जाती है। जो छात्र केवल सूत्रों को रटकर जाते हैं, वे परीक्षा में समय की कमी के कारण पिछड़ जाते हैं, जबकि जिन छात्रों में “डेटा थिंकिंग” होती है, वे आलेखों को देखकर ही सही विकल्प चुन लेते हैं ।
32. JEE Application Thinking
संयुक्त प्रवेश परीक्षा (JEE) के दृष्टिकोण से, सांख्यिकी से हर साल एक अत्यंत वैचारिक प्रश्न पूछा जाता है । JEE मुख्य रूप से माध्य और प्रसरण के परिवर्तनों के गुणों (Transformation Properties of Mean and Variance) पर ध्यान केंद्रित करता है ।
महत्वपूर्ण नियम:
यदि किसी डेटा सेट $x_1, x_2, \dots, x_n$ का माध्य $\bar{x}$ और प्रसरण $\sigma_x^2$ है, और हम प्रत्येक डेटा बिंदु को एक नियतांक $a$ से गुणा करते हैं और उसमें $b$ जोड़ते हैं (अर्थात $y_i = a x_i + b$):
- नया माध्य ($\bar{y}$):$$\bar{y} = a \bar{x} + b$$
- नया प्रसरण ($\sigma_y^2$):$$\sigma_y^2 = a^2 \sigma_x^2$$
- नया मानक विचलन ($\sigma_y$):$$\sigma_y = |a| \sigma_x$$
शिक्षक की विशेष टिप: ध्यान रखें कि प्रसरण और मानक विचलन पर जोड़ने या घटाने (मूल बिंदु के परिवर्तन – change of origin) का कोई प्रभाव नहीं पड़ता, लेकिन गुणा या भाग करने (पैमाने के परिवर्तन – change of scale) का सीधा प्रभाव पड़ता है 。
33. HOTS (Higher Order Thinking Skills) Questions
आइए एक उच्च-स्तरीय वैचारिक प्रश्न को हल करते हैं जो अक्सर प्रतियोगी परीक्षाओं में पूछा जाता है:
प्रश्न:
प्रथम $n$ प्राकृतिक संख्याओं का प्रसरण (Variance) ज्ञात कीजिए ।
हल करने की विचार प्रक्रिया (Thinking Process):
- प्रथम $n$ प्राकृतिक संख्याएँ: $\{1, 2, 3, \dots, n\}$
- प्रथम $n$ प्राकृतिक संख्याओं का योग: $\sum x_i = \frac{n(n+1)}{2}$
- समांतर माध्य ($\bar{x}$):$$\bar{x} = \frac{\sum x_i}{n} = \frac{n(n+1)}{2n} = \frac{n+1}{2}$$
- वर्गों का योग: $\sum x_i^2 = \frac{n(n+1)(2n+1)}{6}$
- प्रसरण का सूत्र:$$\sigma^2 = \frac{\sum x_i^2}{n} – (\bar{x})^2$$
- मानों को रखने पर:$$\sigma^2 = \frac{n(n+1)(2n+1)}{6n} – \left(\frac{n+1}{2}\right)^2$$$$\sigma^2 = \frac{(n+1)(2n+1)}{6} – \frac{(n+1)^2}{4}$$$$\sigma^2 = (n+1) \left[ \frac{2n+1}{6} – \frac{n+1}{4} \right]$$$$\sigma^2 = (n+1) \left[ \frac{2(2n+1) – 3(n+1)}{12} \right]$$$$\sigma^2 = (n+1) \left[ \frac{4n + 2 – 3n – 3}{12} \right]$$$$\sigma^2 = \frac{(n+1)(n-1)}{12} = \frac{n^2 – 1}{12}$$
यह परिणाम न केवल सुंदर है, बल्कि यह दर्शाता है कि जैसे-जैसे $n$ बढ़ता है, प्रसरण वर्गानुपाती रूप से बढ़ता है।
PART 11 — Exam Strategy
34. NCERT Strategy
एनसीईआरटी (NCERT) की पाठ्यपुस्तक आपके परीक्षा की आधारशिला है । बोर्ड परीक्षा में सर्वोच्च अंक प्राप्त करने के लिए निम्नलिखित रणनीतियों का पालन करें :
- प्रश्नावली 13.1: इस प्रश्नावली में माध्य और माध्यिका के सापेक्ष माध्य विचलन की गणना पर पूरा ध्यान दें। गणना को बहुत सावधानी से करें क्योंकि यहाँ जोड़-घटाव की छोटी सी गलती पूरे अंक काट सकती है ।
- प्रश्नावली 13.2: प्रसरण और मानक विचलन की गणना के लिए ‘पद विचलन विधि’ (Step Deviation Method) पर महारत हासिल करें। यह विधि आपकी गणनाओं को बहुत छोटा और त्रुटिहीन बना देती है ।
35. PYQ Trend Analysis
पिछले $5$ वर्षों के बोर्ड प्रश्न पत्रों के विश्लेषण से यह स्पष्ट होता है कि:
- $5$ या $6$ अंकों का दीर्घ उत्तरीय प्रश्न हमेशा वर्गीकृत सतत बारंबारता बंटन के प्रसरण और मानक विचलन की गणना से ही आता है ।
- $2$ या $3$ अंकों का लघु उत्तरीय प्रश्न माध्यिका के सापेक्ष माध्य विचलन की गणना से पूछा जाता है 。
36. Important Questions with Thinking Method
प्रश्न 1 (माध्य के सापेक्ष माध्य विचलन – अवर्गीकृत डेटा):
दिए गए आंकड़ों $38, 70, 48, 40, 42, 55, 63, 46, 54, 44$ के लिए माध्य के सापेक्ष माध्य विचलन ज्ञात कीजिए ।
विचार प्रक्रिया (Thinking Process):
सर्वप्रथम सभी $10$ प्रेक्षणों का समांतर माध्य ($\bar{x}$) ज्ञात करना होगा । तत्पश्चात प्रत्येक प्रेक्षण का माध्य से निरपेक्ष विचलन $|x_i – \bar{x}|$ निकालकर उनका माध्य लेना होगा ।
हल (Step-by-Step Solution):
- माध्य की गणना:$$n = 10$$ $\bar{x} = $$ $$\frac{38 + 70 + 48 + 40 + 42 + 55 + 63 + 46 + 54 + 44}{10}$ $$ = \frac{500}{10} = 50$$
- निरपेक्ष विचलनों की गणना के लिए तालिका बनाना:
| $x_i$ | विचलन $(x_i – \bar{x})$ | निरपेक्ष विचलन $|x_i – \bar{x}|$ | | :—: | :—: | :—: | | $38$ | $38 – 50 = -12$ | $12$ | | $70$ | $70 – 50 = 20$ | $20$ | | $48$ | $48 – 50 = -2$ | $2$ | | $40$ | $40 – 50 = -10$ | $10$ | | $42$ | $42 – 50 = -8$ | $8$ | | $55$ | $55 – 50 = 5$ | $5$ | | $63$ | $63 – 50 = 13$ | $13$ | | $46$ | $46 – 50 = -4$ | $4$ | | $54$ | $54 – 50 = 4$ | $4$ | | $44$ | $44 – 50 = -6$ | $6$ | | योग | | $\sum |x_i – \bar{x}| = 84$ |
- माध्य के सापेक्ष माध्य विचलन की गणना:$$\text{M.D.}(\bar{x}) = \frac{\sum |x_i – \bar{x}|}{n} = \frac{84}{10} = 8.4$$
प्रश्न 2 (माध्यिका के सापेक्ष माध्य विचलन – अवर्गीकृत डेटा):
दिए गए आंकड़ों $13, 17, 16, 14, 11, 13, 10, 16, 11, 18, 12, 17$ के लिए माध्यिका के सापेक्ष माध्य विचलन ज्ञात कीजिए ।
विचार प्रक्रिया (Thinking Process):
अवर्गीकृत आंकड़ों की माध्यिका निकालने के लिए सबसे पहला और अनिवार्य चरण आंकड़ों को आरोही (ascending) क्रम में व्यवस्थित करना है । चूँकि प्रेक्षणों की संख्या सम ($12$) है, इसलिए माध्यिका दो मध्य पदों का औसत होगी ।
हल (Step-by-Step Solution):
- आंकड़ों को आरोही क्रम में व्यवस्थित करने पर:$$10, 11, 11, 12, 13, 13, 14, 16, 16, 17, 17, 18$$
माध्यिका की गणना:
यहाँ प्रेक्षणों की कुल संख्या $n=12$ (सम) है।
जब प्रेक्षणों की संख्या सम होती है, तो माध्यिका ($M$) का सूत्र इस प्रकार होता है:
$$M=\frac{\left(\frac{n}{2}\right)\text{वां पद}+\left(\frac{n}{2}+1\right)\text{वां पद}}{2}$$
यहाँ $n=12$ का मान रखने पर:
$$M=\frac{\left(\frac{12}{2}\right)\text{वां पद}+\left(\frac{12}{2}+1\right)\text{वां पद}}{2}$$
$$M=\frac{6\text{वां पद}+7\text{वां पद}}{2}$$
चूँकि आरोही क्रम में व्यवस्थित आंकड़ों में 6वां पद = 13 और 7वां पद = 14 हैं:
$$M=\frac{13+14}{2}=13.5$$
- निरपेक्ष विचलनों की तालिका बनाना:
| $x_i$ | $|x_i – M| = |x_i – 13.5|$ | | :—: | :—: | | $10$ | $3.5$ | | $11$ | $2.5$ | | $11$ | $2.5$ | | $12$ | $1.5$ | | $13$ | $0.5$ | | $13$ | $0.5$ | | $14$ | $0.5$ | | $16$ | $2.5$ | | $16$ | $2.5$ | | $17$ | $3.5$ | | $17$ | $3.5$ | | $18$ | $4.5$ | | योग | $\sum |x_i – M| = 28$ |
- माध्यिका के सापेक्ष माध्य विचलन की गणना:$$\text{M.D.}(M) = \frac{\sum |x_i – M|}{n} = \frac{28}{12} \approx 2.33$$
PART 12 — पुनरावृत्ति
37. सांख्यिकी One-Shot Revision Notes

- सांख्यिकी क्या है? आंकड़ों का संग्रह, संगठन, विश्लेषण और व्याख्या करने का विज्ञान ।
- अपकिरण के माप (Measures of Dispersion): यह दर्शाते हैं कि आंकड़े अपने औसत मान से कितने फैले हुए हैं ।
- माध्य विचलन (Mean Deviation): विचलनों के निरपेक्ष मानों का औसत । इसकी सीमा यह है कि यह बीजगणितीय रूप से बहुत सुगम नहीं है ।
- प्रसरण (Variance): विचलनों के वर्गों का माध्य । यह ऋणात्मकता की समस्या को दूर करता है ।
- मानक विचलन (Standard Deviation): प्रसरण का धनात्मक वर्गमूल । यह मूल आंकड़ों की इकाई में ही फैलाव को मापता है ।
38. Visual Mind Map
│
┌────────────────────┴────────────────────┐
▼ ▼
[ केंद्रीय प्रवृत्ति के माप ] [ अपकिरण के माप ]
│ │
┌───────────┼───────────┐ ┌───────────┼───────────┐
▼ ▼ ▼ ▼ ▼ ▼
माध्य माध्यिका बहुलक परिसर माध्य विचलन प्रसरण
(Mean) (Median) (Mode) (Range) (M.D.) (Variance)
│
▼
मानक विचलन
(Std. Dev.)
39. Quick Formula Sheet

अवर्गीकृत आंकड़ों के लिए (Raw Data):
- माध्य ($\bar{x}$): $\bar{x} = \frac{\sum x_i}{n}$
- माध्य के सापेक्ष माध्य विचलन: $\text{M.D.}(\bar{x}) = \frac{\sum |x_i – \bar{x}|}{n}$
- माध्यिका के सापेक्ष माध्य विचलन: $\text{M.D.}(M) = \frac{\sum |x_i – M|}{n}$
- प्रसरण ($\sigma^2$): $\sigma^2 = \frac{1}{n}\sum (x_i – \bar{x})^2$
- मानक विचलन ($\sigma$): $\sigma = \sqrt{\frac{1}{n}\sum (x_i – \bar{x})^2}$
वर्गीकृत सतत बारंबारता बंटन के लिए (Continuous Data):
- प्रसरण ($\sigma^2$ – पद विचलन विधि):$$\sigma^2 = h^2 \left[ \frac{\sum f_i u_i^2}{N} – \left(\frac{\sum f_i u_i}{N}\right)^2 \right] \quad $$ जहाँ $$ u_i = \frac{x_i – A}{h}$$ और $$ N = \sum f_i$$
40. Data Summary Charts
| माप का नाम | मुख्य परिभाषा | व्यावहारिक अर्थ | सर्वोकृष्ट उपयोग | सीमा |
| माध्य (Mean) | सभी मानों का औसत योग । | गुरुत्व केंद्र या संतुलन अक्ष। | सामान्य और सममित आंकड़ों के लिए । | चरम मानों से अत्यधिक प्रभावित । |
| माध्यिका (Median) | मध्य स्थान का मूल्य । | $50\%$ आंकड़ों के विभाजन का बिंदु। | अत्यधिक विषम डेटा (जैसे आय) के लिए । | गणितीय विश्लेषण में कम सुगम। |
| माध्य विचलन (MD) | माध्य से औसत दूरी । | आंकड़ों का औसत बिखराव। | बुनियादी और व्यावहारिक व्याख्या के लिए। | मोड ($ |
| मानक विचलन (SD) | वर्गित विचलनों के माध्य का वर्गमूल । | डेटा के फैलाव का मानक पैमाना। | वैज्ञानिक शोध और सांख्यिकीय निष्कर्षों में । | गणना में जटिल और कठिन । |
PART 13 — मेरा अनुभव
41. Classroom Observations
मेरी कक्षा के शिक्षण अनुभवों से मैंने यह सीखा है कि सांख्यिकी पढ़ाते समय छात्रों को डराने वाली सबसे बड़ी बात ‘विशाल तालिकाएं’ (huge tables) और ‘गुणा-भाग’ हैं। जब मैं बोर्ड पर $7$ कॉलम की एक बड़ी तालिका बनाता हूँ, तो गणित में कमजोर छात्र तुरंत अपना ध्यान खो देते हैं।
इस समस्या को हल करने के लिए, मैंने अपनी कक्षा में “कैलकुलेटर-मुक्त सांख्यिकी” (Calculator-free Statistics) का दृष्टिकोण अपनाया है। मैं हमेशा बहुत सरल और छोटी संख्याओं (जैसे $2, 4, 6, 8$) का उपयोग करके पहले अवधारणा की समझ विकसित करता हूँ, और जब छात्र प्रसरण के पीछे के विज्ञान को समझ जाते हैं, तब हम जटिल बोर्ड प्रश्नों की ओर बढ़ते हैं ।
42. Board Copy Mistakes
Board copies check करते समय मैंने देखा है कि छात्र अक्सर निम्नलिखित तीन क्षेत्रों में सबसे अधिक अंक खोते हैं:
छात्रों की सबसे आम त्रुटियाँ (Mistake Analysis Chart)
┌───────────────────────────────┼──────────────────────────────┐
▼ ▼ ▼
[मापांक (Modulus) की उपेक्षा] [संचयी बारंबारता (CF) में त्रुटि]
छात्र मोड लगाना भूल जाते हैं माध्यिका निकालते समय CF तालिका प्रसरण की गणना कर लेते हैं,
और विचलनों का योग शून्य में गलत जोड़ कर बैठते हैं परंतु अंत में उसका वर्गमूल
प्राप्त कर लेते हैं । । लेना भूल जाते हैं ।
इस प्रकार की त्रुटियों से बचने का एकमात्र उपाय परीक्षा कक्ष में प्रत्येक चरण की सचेत रूप से जाँच करना है।
43. Most Common Student Misconceptions
गलत धारणा 1: “यदि दो समूहों का माध्य समान है, तो उनका व्यवहार भी समान होगा।”
यह एक बहुत बड़ी वैचारिक भूल है। दो कक्षाओं के औसत अंक $85$ हो सकते हैं, लेकिन एक कक्षा में सभी छात्रों के अंक $82$ से $88$ के बीच हो सकते हैं (कम मानक विचलन – समरूपता), जबकि दूसरी कक्षा में कुछ छात्रों के $100$ और कुछ के $30$ अंक हो सकते हैं (उच्च मानक विचलन – विषमता) । प्रकीर्णन के माप के बिना केवल माध्य पर विश्वास करना खतरनाक है 。
गलत धारणा 2: “मानक विचलन का मान ऋणात्मक हो सकता है।”
चूँकि मानक विचलन प्रसरण का धनात्मक वर्गमूल है, और प्रसरण हमेशा विचलनों के वर्गों का योग होने के कारण धनात्मक होता है, इसलिए मानक विचलन कभी भी ऋणात्मक नहीं हो सकता । यदि आपका उत्तर ऋणात्मक आ रहा है, तो समझें कि आपने कहीं बुनियादी गणना में गलती की है।
PART 14 — भविष्य की डेटा दुनिया
44. AI और Statistics
कृत्रिम बुद्धिमत्ता (AI) और मशीन लर्निंग (ML) मूलतः उन्नत सांख्यिकी के डिजिटल रूप हैं। जब कोई एआई मॉडल किसी छवि में चेहरे को पहचानता है, तो वह वास्तव में पिक्सेल के रंगों के वितरण का मानक विचलन और प्रसरण माप रहा होता है । चैटजीपीटी जैसे भाषा मॉडल (Large Language Models) सांख्यिकीय संभाव्यता (statistical probability) के आधार पर ही यह तय करते हैं कि आपके प्रश्न के उत्तर में अगला सबसे उपयुक्त शब्द कौन सा होना चाहिए। सांख्यिकी के बिना आधुनिक एआई का महल ताश के पत्तों की तरह ढह जाएगा।
45. Big Data
बिग डेटा की दुनिया में, जहाँ प्रतिदिन टेराबाइट्स डेटा उत्पन्न होता है, सांख्यिकीय प्रतिचयन (statistical sampling) ही एकमात्र साधन है जो इस डेटा को समझने योग्य बनाता है । बिग डेटा एनालिटिक्स पूरे डेटा का विश्लेषण करने के बजाय सांख्यिकीय मॉडलों के आधार पर पूरे सिस्टम के व्यवहार का अनुमान लगाते हैं, जिससे व्यावसायिक और सामाजिक निर्णय क्षण भर में लिए जा सकते हैं 。
46. Predictive Intelligence
पूर्वानुमेय बुद्धिमत्ता (Predictive Intelligence) सांख्यिकी का भविष्य है। मौसम विभाग से लेकर शेयर बाजार के विश्लेषक तक, सभी पिछले डेटा के अपकिरण और प्रकीर्णन का विश्लेषण करके भविष्य के जोखिमों और अवसरों का सटीक अनुमान लगाते हैं 。 यह तकनीक अनिश्चितता को न्यूनतम करके मानव सभ्यता को आने वाले संकटों (जैसे चक्रवात या आर्थिक मंदी) से बचाने में अमूल्य योगदान देती है।
PART 15 — निष्कर्ष
47. आंकड़ों से बुद्धिमत्ता तक की यात्रा
कक्षा 11 गणित अध्याय 13 सांख्यिकी का यह सफर केवल कुछ सूत्रों को याद करने और परीक्षा पास करने तक सीमित नहीं है । यह वास्तव में कच्चे आंकड़ों से मानव मस्तिष्क की बुद्धिमत्ता तक की एक सुंदर और तार्किक यात्रा है ।
इस अध्याय का वास्तविक उद्देश्य आपको एक “डेटा थिंकर” (Data Thinker) बनाना है जो संख्याओं के पीछे छिपे सत्य को देख सके, भ्रामक आलेखों को पहचान सके, और अनिश्चितताओं के बीच भी तार्किक और संतुलित निर्णय ले सके । जब आप इस दृष्टि को विकसित कर लेते हैं, तो आप केवल गणित के छात्र नहीं रह जाते, बल्कि आधुनिक डेटा-संचालित दुनिया के एक साक्षर और प्रबुद्ध नागरिक बन जाते हैं।
Data Thinking Exercises (स्वयं विश्लेषण करें)
गतिविधि 1: “अपने मोबाइल स्क्रीन टाइम का विश्लेषण”
एक सप्ताह तक प्रतिदिन अपने मोबाइल के स्क्रीन टाइम (घंटों में) का डेटा दर्ज करें।
- इस $7$ दिनों के डेटा का समांतर माध्य और माध्यिका ज्ञात कीजिए।
- क्या आपके डेटा में कोई ऐसा दिन है जब आपका स्क्रीन टाइम असाधारण रूप से अधिक या कम था (चरम मान)?
- इस चरम मान के होने और न होने पर माध्य और माध्यिका के मानों में क्या अंतर आता है, इसका विश्लेषण करें ।
गतिविधि 2: “क्रिकेटर की स्थिरता की जांच”
अपने पसंदीदा आईपीएल बल्लेबाज के अंतिम $10$ मैचों के स्कोर का डेटा इंटरनेट से एकत्र करें।
- उसके स्कोर्स का प्रसरण और मानक विचलन ज्ञात कीजिए ।
- इस मानक विचलन के आधार पर उसकी स्थिरता (consistency) पर एक संक्षिप्त रिपोर्ट लिखें ।
कक्षा 11th गणित के नवीनतम पाठ्यक्रम और पाठ्यपुस्तक के लिए, आप NCERT की आधिकारिक वेबसाइट पर जा सकते हैं।”